OK ChatGPT, zostań moim analitykiem danych
W poniedziałek 13 maja OpenAI zaprezentował światu model GPT-4o (o od „omni”). Filmy z prezentacji, wyglądające jak z rzeczywistość doskonałego filmu „Her” Spike’a Jonze obiegły świat. W oczekiwaniu na pełny roll-out tego modelu (na funkcje rozpoznawania video i głos oddający emocje musimy jeszcze poczekać) przetestowałem dostępną wersję GPT -4o, która pojawiła się w moim panelu użytkownika po poniedziałkowej prezentacji. Jestem zachwycony jej możliwościami analizy danych!
To co zaprezentowało OpenAI to na razie demo nie w pełni dostępne dla konsumentów. Na pełną multimodalność (rozumienie obrazu z kamery i bardzo swobodną rozmowę bez opóźnień, głos chata oddający ludzkie emocje) będziemy musieli jeszcze chwilę poczekać. Jednak nie zmienia to faktu, że sam model został już udostępniony płatnym subskrybentom. Co więcej GPT – 4o będzie dostępny również dla użytkowników, którzy nie opłacają 20$ abonamentu (tak…zapłacisz danymi, które OpenAI chce zebrać ;). Jeśli posiadasz darmowe konto OpenAI, to sprawdź, czy nie pokazuje Ci się już opcja włączenia modelu GPT- 4o zamiast GPT3.5
Ponieważ jak napisałem, czekamy na pełną multimodalność to w międzyczasie przetestowałem inny aspekt nowego modelu OpenAI, który mnie zachwycił. Chodzi mianowicie o Code Interpter.
ChatGPT za pomocą języka Python jest w stanie przeprowadzić naprawdę rozległe analizy danych nawet na sporych plikach (odpowiednio sformatowany) Excel lub CSV. Niestety, w modelu GPT 4.0 wielokrotnie taka analiza nie dochodziła do skutku z powodu błędu lub dochodziło do halucynacji (model pisał nieprawdę).
To co zahcwyciło mnie w modelu GPT-4o to łatwość i SZYBKOŚĆ z jaką ten agent wykonuje analizy. Poniżej kilka przykładów.
Analiza 30 tyś wierszy danych o nieruchomościach na wynajem od AirBnB w Nowym Jorku

Proszę ChatGPT o analizę pliku z 30 tyś wierszy danych
Plik z data setem znalazłem na stronie: https://public.tableau.com/app/learn/sample-data
Nawet nie siliłem się na wyrafinowany prompt ;) Po prostu wrzuciłem plik i poprosiłem o analizę. Na wstępie ChatGPT – 4o prawidłowo odczytał strukturę danych i sam zaproponował możliwe analizy:

Możliwe analizy, które podpowiedział ChatGTP
Poprosiłem o wykonanie pierwszej zaproponowanej analizy.

Wykres pudełkowy pokazujący zróżnicowanie cen na AirBnB w zależności od dzielnicy w NY
Otrzymałem bardzo ładny wykres pudełkowy (box plot), w którym środkowe grube linie to mediany dla poszczególnych segmentów analizowanych danych. Górna krawędź kolorowego pudełka wyznacza 3 kwartyl (czyli 75% analizowanych danych w tym segmencie jest mniejsza od tej wartości). Natomiast dolna krawędź kolorowego pudełka oznacza zakres 1 kwartyla (25% danych w analizowanych segmencie jest mniejsza od tej wartości).
Następnie poprosiłem model aby skupił się wyłącznie na segmencie prywatnych pokoi.

Również i tutaj otrzymałem wykres pudełkowy dość wyraźnie pokazujący, że najdroższa dzielnicą jest Manhattan.
W kolejnym kroku poprosiłem Chata o wybranie 10 najdroższych kodów pocztowych.

Chat przygtował dla mnie 10 najdroższych kodów pocztowych NY wg mediany ceny
A kiedy to zrobił, poprosiłem o identyfikacje tych kodów (tutaj Chat korzystał z Internetu, gdyż w pliku takich oznaczeń nie było) i przedstawienie mediany cen w tych obszarach na wykresie.

10 (a właściwie 9) najdroższych zip codes NY na AirBnB przedstawione na wykresie.
Co prawda ChatGPT nie mógł zidentyfikować jednego z kodów ale to niewielka niedogodność w perspektywie całej analizy, która nie zajęła nawet 5 minut…
Analiza Mistrzów Wimbledonu w latach 1877 – 2016
Te dane również pobrałem ze strony https://public.tableau.com/app/learn/sample-data
Nauczony doświadczeniem nie siliłem się na wyrafinowany prompt (prompty mają jednak ogromne znaczenie we wszystkich innych kreatywnych zadaniach z Chatem GPT)

ChatGPT - 4o odczytuje strukturę danych w pliku z informacjami na temat finałów Wimbledonu
Najpierw model GPT- 4o odczytał strukturę pliku i zaproponował kilka analiz.
Poprosiłem o pokazanie mistrzów Wimbledonu po narodowości (ponieważ nie doprecyzowałem płci, model wziął pod uwagę i kobiety i mężczyn dlatego później poprosiłem aby wykonał analizę ponownie ale biorąc od uwagę wyłącznie mężczyzn.

Liczba mistrzów Wimbledonu wg narodowości
Następnie chciałem zobaczyć jaki wynik setu pojawiał się najczęściej w finale.

Najczęstsze wyniki setów rozegranych w męskich finałach Wimbledonu
Zainteresowało mnie również jak zmieniała się w czasie długość finału Wimbledonu. Poprosiłem zatem o wizualizację tego zagadnienia. Dostałem kompletnie nieczytelny wykres liniowy. Dlatego po prostu poprosiłem o poprawkę:
“Why do you present match duration with line chart? Can you propose better chart style to visualize this data?”
Ponieważ ChatGPT -4o to zdolne dziecko, tylko troszkę leniwe to po tej prośbie otrzymałem bardzo czytelny wykres punktowy wraz z linią trendu.

Długość trwania finału Wimbledonu na przestrzeni lat.
Napisanie programu w Pythonie do liczenia Break Even Point
ChatGPT - 4 już od samego początku gdy został udostępniony pisze skrypty w języku Pythona (a także w innych językach programowania). Natomiast Model GPT-4o zdecydowanie pszyspieszył i wypluwa linijki kodu błyskawicznie. Poniżej ciekawy przykład:
Poprosiłem model aby wcielił się w nauczyciela, który chce wytłumaczyć uczniom szkoły średniej co to jest break even point.

Początkowa prośba o wytłumaczenie koncepty break even point na przykładzie kawiarni
GPT 4 - 4o opisał całe zagadnienie naprawdę obszernie. Wystarczy spojrzeć poniżej:

ChatGPT objaśnia zestaw danych, których używa do wytłumaczeni break even point
Miałem nadzieję, że na koniec ChatGPT przygotuje wykres ilustrujący przykład który wymyślił. Jednak ChatGPT -4o zrobił coś lepszego. Napisał kod w języku Python, który po wklejeniu do edytora kodu daje ten wykres.
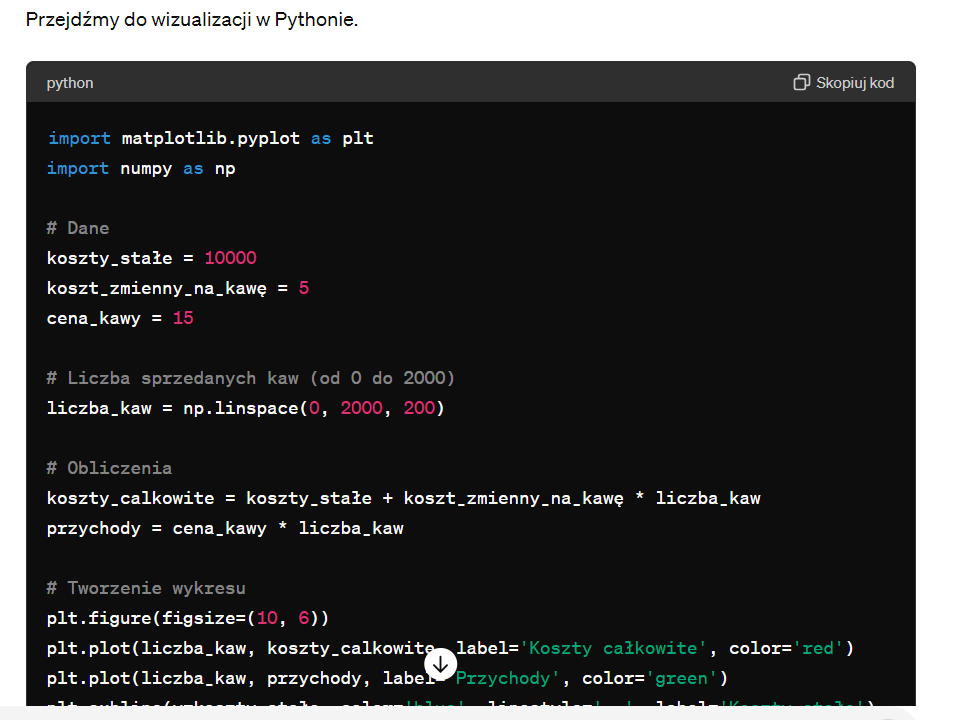
Kod w języku Python, który przygotował ChatGPT
Skoro tak…to spontanicznie poprosiłem ChataGPT o napisanie programu, który będzie prosił o 3 zmienne (koszty stałe, koszty zmienne, cena kubka kawy) i uczeń będzie mógł sam sprawdzać jak zmienia się break even point w zależności od przyjętych wartości zmiennych.

Prosty program w Pythonie, w którym podajesz 3 zmienne a program liczy break even i ilustruje go wykresem.
ChatGPT wypluł 51 linijek kodu ( o jego jakości nie mogę się wypowiadać, wszak nie jestem programistą…), które to. przekleiłem do replita.
(przy okazji replit.com - najlepsze miejsce w Internecie aby uczyć się programowania kiedy nie ma się o tym zielonego pojęcia).
Kiedy kliknąłem “run” program zadziałał zgodnie z oczekiwaniami. Podałem 3 zmienne (7tyś, 4pln, 12pln) a program policzył ile kaw muszę sprzedać aby osiągnąć próg rentowności mojej kawiarni.
Podsumowując. Oczywiście, że czekam na możliwość włączenia kamery przejechania po moim półkach z książkami i poproszeniem ChataGPT aby mi je skatalogował w formacie csv.Jednak dopóki to nie nastąpi poeksploruje jeszcze jego nienajgorsze mozliwości analizy danych. Na razie jestem zachwycony.